ถ้าแบ่งยุคของ Internet ในตอนนี้อาจแบ่งได้ 2 ยุค และเรากำลังก้าวไปสู่ยุดที่ 3 ในไม่ช้านี้ ในยุดแรก Web 1.0 นั้นเป็นเรื่องของการที่ผู้ให้บริการนำเสนอข้อมูลให้กับบุคคลทั่วไป โดยทำในลักษณะเดียวกับหนังสือทั่วไป ที่ผู้อ่านมีส่วนร่วมน้อยมากในการเติมแต่งข้อมูล แต่ในยุคของ Web 2.0 บุคคลทั่วไปคือผู้สร้างเนื้อหา และนำเสนอข้อมูลต่าง ๆ จาก Web 2.0 ในเปลือกนัท ทำให้เราเข้าใจว่าในยุคที่ 2 นั้นเป็นเรื่องของการแบ่งปันความรู้ซึ่งกันและกันอย่างแท้จริง โดยการสร้างเสริมข้อมูลสารสนเทศ ให้มีคุณค่าและมีข้อมูลที่ถูกต้องที่สุด ดังตัวอย่างที่เป็นสิ่งที่ทุกคนคงรู้จักกันดีอย่าง Wikipedia ทำให้ความรู้ถูกต่อยอดไปอยู่ตลอดเวลา ข้อมูลทุกอย่างได้มาจากการเติมแต่งอย่างไม่มีที่สิ้นสุด เกิดจากการคานอำนาจของข้อมูลของแต่ละบุคคลทำให้ข้อมูลนั้นถูกต้องมากที่สุด และจะถูกมากขึ้นเมื่อเรื่องนั้นถูกขัดเกลามาตามระยะเวลายาวนาน
และวันนี้ Web 3.0 กำลังจะมา เป็นการนำแนวคิดของ Web 2.0 มาทำให้ Web นั้นสามารถจัดการข้อมูลจำนวนมาก ๆ โดยอย่างที่เรารู้กันดีว่าผู้ใช้ทั่วไปนั้นเป็นผู้สร้างเนื้อหา ได้เพิ่มจำนวนมากขึ้น เช่นการเขียน Blog, การแชร์รูปภาพและไฟล์มัลติมีเดียต่าง ๆ ทำให้ข้อมูลมีจำนวนมหาศาล ทำให้จำเป็นต้องมีความสามารถในการข้อมูลดังกล่าวอย่างหลีกเลี่ยงไม่ได้ โดยเอาข้อมูลต่าง ๆ เหล่านั้นมาจัดการให้อยู่ในรูปแบบ Metadata ที่หมายถึงข้อมูลที่บอกรายละเอียดของข้อมูล (Data about data) ทำให้เว็บกลายเป็น Sematic Web กล่าวคือเว็บที่ใช้ Metadata มาอธิบายสิ่งต่าง ๆ บนเว็บ ซึ่งในตอนนี้เราจะเห็นกันทั่วไปนั่นคือ Tag นั้นเอง โดยที่ Tag ก็คือคำสั้น ๆ หลาย ๆ คำ ที่เป็นหัวใจของเนื้อหา เพื่อทำให้เราสามารถเข้าถึงเนื้อหาต่าง ๆ ได้ด้วยการใช้ Tag ต่าง ๆ เพื่อเข้าถึงข้อมูลที่เกี่ยวข้อง แต่แทนที่ผู้ผลิตเนื้อหาจะใส่เอง แต่ตัว Web จะทำหน้าที่ประมวลผลข้อมูลและวิเคราะห์ข้อมูลเหล่านั้น แล้วให้ Tags ตามความเหมาะสมให้เราแทน
โดยเมื่อได้ Tag มาแล้ว ข้อมูลแต่ละ Tag จะมีความสัมพันธ์กับอีก Tag นึงโดยปริยาย เช่นข้อมูลเกี่ยวกับบริษัท Apple ก็จะมี Tag ที่เกี่ยวกับ Computer, iPod, iMac … และ Tag ที่มีเนื้อหา Computer ก็มี Tag ที่เชื่อมโยงกับ Tag ที่มีเนื้อหาด้าน Electronic โดยจะเชื่อมโยงแบบนี้ไปเรื่อย ๆ ทำให้ข้อมูลมีการเชื่อมโยงกันเหมือนฐานข้อมูลที่มีความสัมพันธ์กันในเชิงข้อมูล ทำให้อินเตอร์เน็ตกลายเป็นฐานข้อมูลความรู้ขนาดใหญ่ ที่ข้อมูลทุกอย่างถูกเชื่อมต่อกันอย่างเป็นระบบมากขึ้น
เนื้อหาบางส่วนจาก Web 3.0 ในเว็บ BlogSpotting, BusinessWeek Online
Web 1.0 = Read Only, static data with simple markup
Web 2.0 = Read/Write, dynamic data through web services
Web 3.0 = Read/Write/Relate, data with structured metadata + managed identity
Some people say that web 2.0 is the network as a OS. By the time of web 3.0 we should have the web behaving more like a single application with many features then an OS with many apps.
Addi at October 25, 2006 07:05 PM
* Web 1.0 allowed us to share software and files resulting in a fundamental reduction in the duplication of effort during problem solving.
* Web 2.0 services now allow us to share more sophisticated functionality but at a smaller granularity promoting greater reuse of solutions and therefore another drastic reduction in the duplication of effort.
* Web 3.0 will allow us to shunt in human intelligence in a dynamic cooperative manner, with the help of a tightly connected network of personal A.I. assistants, resulting in an explosive improvement in our ability to share solutions and talent.
Robert Oschler at December 12, 2006 01:01 AM
Web 3.0 is coming. The Web is the User Interface to the Internet. The Internet is not the Web.
They both continue to evolve through the application of creative intelligence by people all over this planet to the interconnection of computing devices and machines (the Internet) and the content that is consumed by a living end-user (via the Web’s Browser).
Andy Carvin’s comment was the closest when he referenced Tim Berners-Lee’s notion of the read-write web. HTML was originally derived from the document mark up language used for technical documentation. This was to enable the display of Content for an end-user to consume (read and view). The point is the Web is about communications, not the technology infrastructure, not the wired or wireless device used to access the infrastructure to enable communications, and not the business opportunities that sprout from the capabilities of modern information technology. Execution will be another Internet component, just as VOIP is and IPv6. The interface to the content that is posted, presented, created, and generated is made humanly available via the Web.
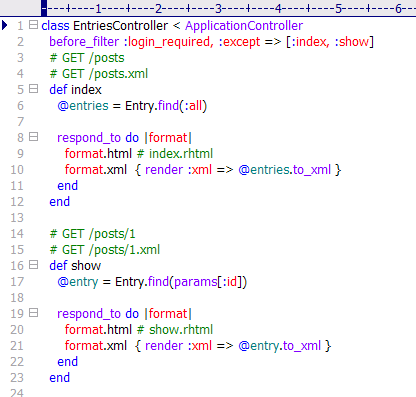
So, if we follow Tim Berners-Lee’s notion of the Web as communications, I would propose that the Web 3.0 can be defined via the following logic:
[1] Web 1.0 was about making information, regardless of media, available for push to and pull by individual users.
[2] Web 2.0 is Web 1.0 with the addition of the capability for individual users to push information and media to the Web site.
Therefore,
[3] Web 3.0 will be Web 2.0 with the addition of individuals being able to share as a group and in real time information and media.
Just as game development has evolved to enable massively multiplayer online games (MMOG), the sharing of an environment will allow similar real time communication that the MMOG players enjoy.
Semantic Web is a combination of extrapolated database technology and algorithm based automaton agents. The output of applications built on the Semantic Web will be served through the Internet to the Web Browser, whether that Browser resides on or is built into a mobile phone, a refrigerator, a television set, or a computer.
The Web is all about communications.
Thanks for listening.
Harrison Rose
Silicon Valley
Harrison Rose at January 14, 2007 09:24 PM