จากตอนที่ เทคนิดการทำ SEO เบื้องต้นที่ควรรู้ (reloaded) ที่ทิ้งท้ายไว้ใน comment ว่าจะพูดถึงเรื่องนี้วันนี้เราขอพูดถึงเรื่องนี้ซะเลยครับ
PageRank หรือในอีกชื่อคือ PageRank of E เรียกสั้น ๆ ว่า PR หรือ PR(E) เป็น graph analysis algorithm ในทฤษฎี graph รูปแบบหนึ่ง โดยถ้าใครเรียนในวิชาพวก project management, software engineering หรือ software analysis จะได้เจอในส่วนของ Critical Path Analysis และ PERT (Program Evaluation & Review Technique) โดยที่ PageRank นั้นพัฒนาขึ้นที่ Stanford University โดย Larry Page และ Sergey Brin โดยเป็นงานวิจัยในระดับปริญญาเอก เพื่อการค้นคว้าหาวิธีการใหม่ ๆ ในการค้นหาข้อมูล โดยเริ่มต้นงานวิจัยในปี 1995 และต้นแบบก็สามารถใช้งานได้ในชื่อของ Google ในปี 1998 ในความเป็นจริงที่ว่า PageRank เป็นเครื่องหมายทางการค้าของ Google Inc. โดยมีหมายเลขสิทธิบัตรอยู่ที่ U.S. Patent 6,285,999 แต่ว่าสิทธิบัตรไม่ได้เป็นของ Google Inc. แต่เป็นของ Stanford University (The Board of Trustees of the Leland Stanford Junior University, Stanford, CA)
โดยที่ Page Rank ตามความหมายที่ Google ให้ไว้คือ
PageRank relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page’s value. In essence, Google interprets a link from page A to page B as a vote, by page A, for page B. But, Google looks at more than the sheer volume of votes, or links a page receives; it also analyzes the page that casts the vote. Votes cast by pages that are themselves “important” weigh more heavily and help to make other pages “important”.
โดยถ้าจะให้เข้าใจได้ง่าย ๆ นั้นก็คือว่า (แปลสรุปเป็นไทย)
หน้าใด ๆ บน internet ยิ่งมีการลิงก์ถึงหน้านั้นมาก ๆ ก็ยิ่งได้รับคะแนนสูงขึ้น และถ้าหน้าเหล่านั้นที่มีคะแนนสูง ๆ มีลิงก์ไปหน้าอื่น ๆ หน้าที่ลิงก์ไปปลายทางก็จะได้รับคะแนนตามสัดส่วนไปด้วยและจริง ๆ แล้วเนี่ย แนวคิดนี้เป็นแนวคิดที่ได้จากการอ้างอิงของหนังสือในแวดวงวิชาการ โดยมีแนวคิดที่ว่า “หนังสือเล่มใด มีความน่าเชื่อถือว่าสูงมักจะมีการนำไปใช้อ้างอิงอยู่เสมอ ๆ”
ตัวอย่างเช่น
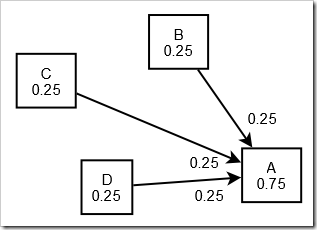
ตามรูปด้านล่างนี้ครับ
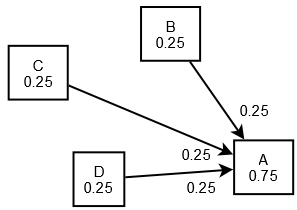
เรามีเว็บ A, B, C และ D โดยที่ทุกหน้ามี PR(E) อยู่ที่ 0.25
โดยที่ B, C และ D นั้นลิงก์ไปที่ A โดยที่ A จะได้คะแนนไป 0.25 จากทุก ๆลิงก์เป็น 0.75
โดยเราจะเขียนเป็นสมการว่า
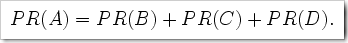
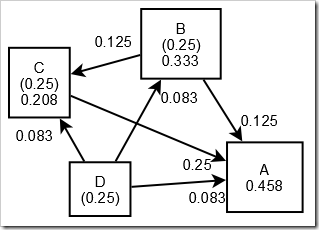
ต่อมาเมื่อ B ทำลิงก์ไปที่ C และ D ทำลิงก์ไปที่ A, B และ C ค่า PR(E) ของตนที่จะให้กับหน้าปลายทางจะถูกหารตามจำนวนลิงก์ที่ลิงก์ออกไป ส่วนหน้า D ตามตัวอย่างที่ไม่มีลิงก์เข้ามาที่หน้านี้ ก็จะยังคงค่าคะแนนที่ 0.25 เท่าเดิม (แต่ในความเป็นจริงแล้วจะเป็น 0 หรือค่าตั้งต้นใด ๆ )
PR(B) / 2 = 0.125 / link
PR(D) / 3 = 0.083 / link
PR(C) / 1 = 0.25
จะได้สมการดังนี้
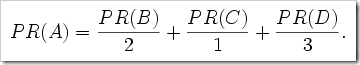
เราเรียกวิธีการแบบนี้ว่า link-votes หรือบางครั้งอาจจะเรียกว่า outbound link ก็ได้ โดยใช้ฟังค์ชัน L() แทนด้วยด้วยจำนวน outbound link
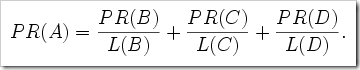
โดยสรุปให้สั้นได้ว่า
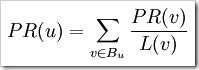
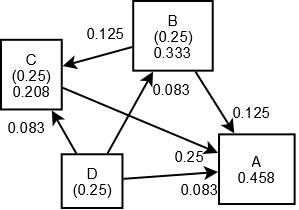
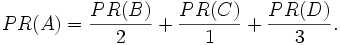
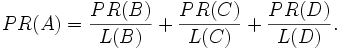
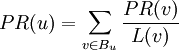
จากตัวอย่างด้านบนที่ได้กล่าวไปนั้น เอามาสร้างแบบจำรองได้ดังรูปด้านล่างนี้ครับ
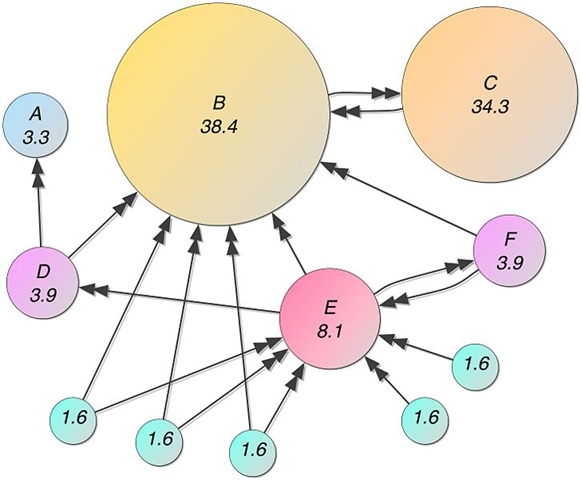
Mathematical PageRanks (out of 100) for a simple network (PageRanks reported by google are rescaled logarithmically). Page C has a higher PageRank than Page E, even though it has fewer links to it: the link it has is much higher valued. A web surfer who chooses a random link on every page (but with 15% likelihood jumps to a random page on the whole web) is going to be on Page E for 8.1% of the time. (The 15% likelihood of jumping to an arbitrary page corresponds to a damping factor of 85%.) Without damping, all web surfers would eventually end up on Pages A, B, or C, and all other pages would have PageRank zero. Page A is assumed to link to all pages in the web, because it has no outgoing links.
นั้นหมายความว่ายิ่งเรามีลิงก์กลับมาหน้าของเว็บเรามากเท่าใด ก็ยิ่งได้รับ PR(E) สูงมากขึ้นเท่านั้น แต่เราต้องผสมกับการใช้ SEO เข้าร่วมด้วยเช่นกัน
ถ้าจะให้สรุปง่ายก็คือ SEO นั้นทำให้ Crawler เข้ามา index ข้อมูลของเราได้ง่ายมากขึ้น และนำข้อมูลของเราไปจัดอันดับ โดยอ้างอิงจาก PR(E) ด้วยเช่นกัน โดยการที่จะได้ PR(E) สูง ๆ นั้นเว็บของเราต้องมีลิงก์ที่อยู่บนเว็บที่มี PR(E) ที่สูงกว่ามาก ๆ เพื่อช่วยดึงค่า PR(E) ของเว็บของเราให้สูงขึ้นตามไปด้วย ซึ่งบางเว็บที่อยากให้เว็บตัวเองมีค่า PR(E) สูง ๆ มักทำ spam comment หรือ content ขึ้นมาเพื่อสร้างลิงก์ต่าง ๆ ให้วิ่งเข้าหาเว็บหลักของตัวเอง ซึ่งตาม blog หรือ community มักจะโดย spam กันอยู่ในช่วงหลายปีที่ผ่านมานี้นั้นเองครับ
ปล. ข้อมูลต่าง ๆ ใน entry นี้เป็นระดับเบื้องต้นครับ การจัด PR(E) ของ Google นั้นมีตัวประกอบอื่น ๆ อีกมากมายครับ แต่ที่ผมนำเสนอนี้เป็นส่วนหลักของการทำงานของ PageRank โดยรวมครับผม
เอกสารอ้างอิง
- PageRank by Wikipedia
- Our Search: Google Technology by Google
- How Google Finds Your Needle in the Web’s Haystack by the American Mathematical Society
- Original PageRank U.S. Patent- Method for node ranking in a linked database – September 4, 2001
- PageRank U.S. Patent – Method for scoring documents in a linked database – September 28, 2004
- PageRank U.S. Patent – Method for node ranking in a linked database – June 6, 2006
